* 64-bit나 VT도 지원하는 Silverthorne
Intel의 저소비전력 x86 CPU [LPIA(Low Power Intel Architecture)] 인 [Silverthorne(실버손)]의 정체가 보이
기 시작했다. 현재, 미 샌프란시스코에서 개최되고 있는 반도체 컨퍼런스 [ISSCC(IEEE International Solid-
State Circuits Conference) 2008] 에서는 Inrel이 Silverthorne의 개요에 대해서 첫 발표를 했다.
Silverthorne은 TDP(Thermal Design Power,열설계소비전력)을 2W 이하로 내리는 것을 타겟으로 한 초저소비전력
CPU로서 설계되었다. 전력을 내리면서 PC용 CPU와 동등한 기능(명령)을 갖추었다. Core 2 Duo의 SSE3까지의 명
령셋과 호환되고, 64-bit확장 [Intel 64]나 Intel Virtualization Technology(VT)도 지원한다. 또한 퍼포먼스도
1세대전의 PC용 모바일 CPU의 로우엔드에 필적한다.
이러한 성능과 기능의 목적을 위해 Intel은 Silverthorne에서는 2명령 이슈의 인 오더(In-Order)실행의 파이프
라인을 선택해, 2스레드의 멀티스레딩 기능을 갖추었다.
[아웃 오브 오더(out-of-order) 실행을 시작으로, 어려가지 설계를 분석했다. 그 결과 인 오더 실행에서 멀티
이슈 머신, 멀티 스레드가 최고의 전력대 성능비를 달성할수 있는 것을 발견했다] 라고 ISSCC에서 발표를 한
Intel의 Gianfranco Gerosa 씨는 설명했다.
Intel은 PC클래스의 기능을 가진 모바일 기기나 저가격 PC를 LPIA계 CPU로 커버할려고 하고 있다. 그때문에
Silverthorne은 휴대기가용 CPU로서는 몇가지 유니크한 기능이 보인다. Silverthorne의 포인트는 트랜지스터 수
를 줄어서 작은 크기의 칩으로 만들면서 CPU 자체를 고클럭으로 돌려 멀티스레드 성능을 높이는 것으로 퍼포먼
스를 버는 것에 있다.
* 2Ghz 급의 고 클럭을 타겟으로
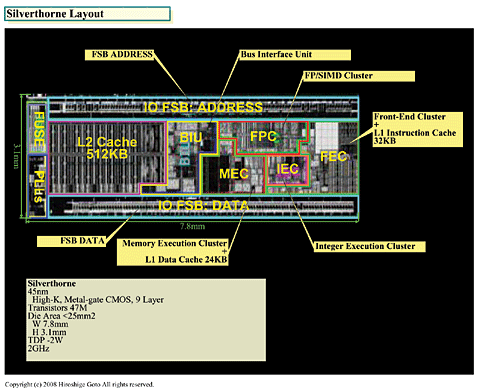
Silverthorne의 CPU자체의 사이즈는 상당히 작다. 7.8x3.1mm(가로x세로)으로 설계상의 다이사이즈(반도체본체의
면적)은 약 24평방mm대 (발표에서는 25평방mm이하로 되어 있다). 이것은 메인스트림 PC용 CPU의 약 1/4의 사이
즈이다. [CPU 코어 끼리 비교해도, PC용 CPU의 약 1/4 사이즈] 라고 Cerosa씨는 말했다. 트랜지스터 수는 47M
(4,700만개)이고 45nm판 Core 2 Duo(Penryn 6M)의 410M(4억 1000만개)의 1/9 정도이다.
작은 다이사이즈를 실현하기 위해, Silverthorne에서는 인 오더 형의 명령실행을 채택했다. 이것은 PC용 CPU의
대부분이 아웃 오브 오더 형 실행을 채용하고 있는것과는 대조적이다. 하지만 아웃 오브 오더 실행형은 명령을
병렬로 실행할수 있기 위해 명령 스케줄링에 팽대한 리소스가 필요해진다. 그때문에 PC용 CPU의 비대화와 전력
효율의 악화의 원인이 되었다. Silverthorne에서는 아웃 오브 오더를 제거하여 상당한 양의 트랜지스터와 다이
면젹의 절약을 실현했다.
또한 그 뿐만 아니라 Silverthorne에서는 실행 유닛 군도 상당히 절약하고 있다. 예를들면, SIMD정수승산 유닛
은 스칼라 정수승산 명령도 실행한다. 겸용하게 되면 유닛 수를 미니멈하게 줄이고 있다. 철저하게 깐깐한 설계
가 Silverthorne의 특징이다.
CPU를 단순화 하게 되어 전력소모의 원인인 트랜지스터 수를 줄이는 것은 저소비전력 CPU의 기본적인 접근이다.
그러나 Silverthorne에서는 저소비전력 CPU로서는 유니크한 점이 있다. 보통 저소비전력 CPU는 파이프라인 단수
는 얇게 하고, 동작주파수는 낮게 잡는다. 파이프라인 수를 깊게 하면 동작주파수를 올릴수 있지만 래치 회로
등이 증가하게 되어 소비전력이 증가하게 되기 때문이다.
그런데 Silverthorne은 파이프라인은 16스테이지로 어느정도 깊이를 가지고 있다, 저전력이지만 2GHz 전후의 주
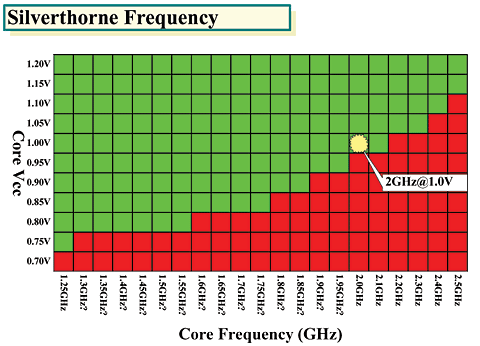
파수를 타겟으로 하고 있다. 아래는 ISSCC에서 발표된 Silverthorne의 주파수/전압 차트를 보강한 것이다. 원래
차트에는 주파수 항목의 숫자가 들어있지 않았다. 오른쪽의 최고주파수가 2.5Ghz, 맨 가운데의 포인트가 2GHz에
1V, 왼쪽의 최저주파수가 1.25GHz로 표시되어 있다. 그때문에 2GHz에서 아래쪽이 0.05GHz씩 되어있는 것으로 판
단되어 보강했다. 이것을 봐도 알 수 있지만 Silverthorne은 1V 정도의 전압에서 2GHz를 마크하고 있고 0.8V 이
하에서도 1GHz를 충분히 넘고 있다.
* 싱글사이클 실행으로 결정된 파이프라인
타겟 블럭을 보면 트랜지스터 수가 적은 CPU를 그럭저럭 높은 클럭으로 움직여서 퍼포먼스를 올리는 것이
Silverthorne의 컨셉 같이 보인다. 그 결과, 트랜지스터 수가 많은 PC용 CPU를, 무리하게 저전압으로 구동해서
저주파수로 동작시키는 것 보다 뛰어난 퍼포먼스/소비전력을 얻을 수 있는 것으로 판단했다고 보인다.
Silverthorne의 16스테이지 파이프라인은 NerBurst 마이크로 아키텍쳐의 20~31스테이지라고 하는 깊은 파이프라
인과 비교해보면 적다. 하지만 코어 마이크로 아키텍쳐(Core MA)의 14스테이지보다 깊다. 인 오더 실행의
Silverthorne이 아웃 오브 오더 실행의 Core MA보다 파이프라인의 복잡도가 적다는 것을 생각해보면,
Silverthorne의 파이프라인은 깊다. 실제로는 Silverthorne의 파이프라인은 인 오더 실행에서의 성능을 올리기
위해, 어드레스 생성과 L1데이터 캐쉬 억세스의 3스테이지 분이 첨가되어 있다. 그것을 제외하면 13스테이지이
지만 그래도 Core MA와 거의 같은 레벨이 된다.
Gerosa씨에 따르면 파이프라인 단수는 싱글사이클 실행의 컨셉에서 정해졌다고 한다.
[이 16스테이지 파이프라인은 우리가 싱글사이클 실행을 유지하는 것을 바라는 것으로 결정되었다. 'EX1'이 실
행 스테이지이고 1사이클로 정리되어 있다. 싱글 사이클 실행한 것으로 1사이클(스테이ㅈ)당 게이트 수가 결정
된다. 그것을 받아서 우리는 파이프라인을 구축하고 퍼포먼스를 확장하기 위한 사양을 추가했다]
정수연상을 1사이클로 실행하는 경우, 정수연상 버스의 로직의 양에서 1스테이지의 최대 게이트 수(=딜레이)가
결정된다. 이후는 파이프라인의 다른 부분은 그 게이트 수(=딜레이)에 정리되도록 잘라냈다고 추정된다. 지금
CPU에서는 실은 명령실행자체에는 별로 시간이 걸리지 않는다. 게이트 수를 먹고 있는 것은 명령 디코드나 스케
줄, 레지스터 억세스 등의 실행이외 부분이다. 실행 스테이지에 맞춰서 다른 스테이지의 게이트 수를 규정하면
싱글 사이클 실행의 범위에서 최대한의 동작주파수를 달성할수 있는 것이다.
* 명령 페치와 디코드의 스테이지가 깊은 Silverthorne
Silverthorne의 16스테이지 중 최초 6스테이지는 Intel이 [Front-End Cluster]라고 부르는, 명령 페치&디코드
부분에서 실행된다. 최초 3스테이지가 되는 IF(Instruction Fetch)1~3이, 명령을 L1명령캐쉬에서 끄집어내는 명
령 페치 부분. 여기에 L1명령 캐쉬 억세스의 딜레이도 포함되어 있다고 추정된다.
다음 3스테이지는 명령 디코드로, ID(Instruction Decode)1~3으로 구성되어 있다. Silverthorne에서는 PC&서버
용 CPU처럼 x86명령을 완전히 분해하는 것은 아니다. 하지만 가변장의 x86명령을 캐쉬 라인에서 끄집어내서 실
행하기 쉬운 포맷으로 하기 위해, 3사이클을 걸고 있다. 명령 디코드는 x86계 명령에서 가장 어려운 부분중 하
나로, 그것을 위해 스테이지 수가 필요하다고 추정된다.
파이프라인에서는 보이지 않지만, 실제로는 명령 페치와 명령 디코드 사이에는, 프리페치 메커니즘에서 집어넣
은 명령의 버퍼가 있다. Silverthorne의 2스레드의 하드웨어 멸티스레딩이 있기 때문에 명령 프리페치 버퍼는
스레드 별로 2계통의 버퍼로 구성되어 있다.
명령 디코드 스테이지의 디코더는 2명령층으로 IA-32명령을 동시에 2명령씩 디코드할 수 있다. 디코드된 명령은
인스트럭션 캐쉬에 들어간다. 이것도 스레드 별로 준비되어 있다.
다음 명령 디스패치는 2스테이지 구성이다. Silverthorne은 명령 디스패쳐에서 동시에 실행할 수 있는 2명령을
실행 파이프라인에 발행하는 2이슈 머신이 되어있다. 이 부분에서는 실제로는 스레드 스케줄링을 하고 있다. 발
행하는 2명령을 1개의 스레드에서 선택하는 것도, 2개의 스레드에서 1명령씩 선택하는 것도 가능하기 때문이다.
2개의 스레드의 명령을 1사이클에서 혼재시켜서 실행가능한 SMT(Simultaneous Multithreading)이 되어 있다. 사
이클단위에서 스레드를 전환시킨다는 방식은 아니다. 그 때문에 Silverthorne에서는 실행 파이프라인의 공백을
2스레드에서의 명령으로 채울 수가 있다.
명령발행의 다음 차례는 소스 오페랜드의 읽기. 이것을 물리 레지스터 파일이 작아서 1스테이지로 끝난다. 다음
은 메모리 억세스의 어드레서 생성 AG(Address Generation) 스테이지로 억세스하는 메모리의 어드레스를 이 스
테이지에서 생성한다. AG가 1스테이지이고 다음 2사이클이 L1데이터 캐쉬의 DC(Data Cache)1~2가 된다.
데이터 캐쉬 억세스를 경유해서, 오페랜드가 모인 시점에서 실행 스테이지인 EX1이 된다. 여기가 싱글사이클 실
행이고, 계속되는 2스테이제어서 열외와 멸티스레딩의 핸들링을 행한다. 마지막 16스테이지째에서 커밋하고 라
이트백해서 파이프라인이 끝난다. 다음은 Silverthorne의 저전력기능의 세부사항에 대해서 리포트하겠다.
출처 : watch.impress.co.jp