* 작은 CPU를 고속으로 돌리는 것이 Silverthorne의 아이디어
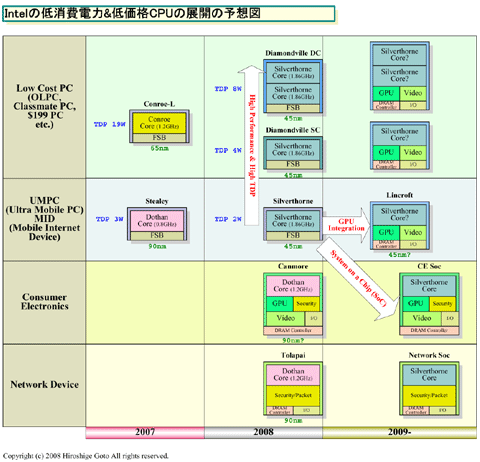
Intel의 초저소비전력 CPU [Silverthorne]의 타겟은 명료하다. Scorpion같은 ARM계의 고퍼포먼스
CPU 보다 높은 퍼포먼스 영역을, 리즈너블한 퍼포먼스/소비전력에서 실현한다. 그로인해 PC와 휴대
폰의 틈새에 있는 UMPC(Ultra Mobile PC)나 MID(Mobile Internet Device)라고 하는 모바일 기기의
CPU(휴대전화측의 표현으로는 어플리케이션 프로세서)의 자리를 차지하는 것이다.
Silverthorne을 포함하는 LPIA(Low Power Intel Architecture)계 CPU와, 그 파생 프로세서 군은, 그
외에도 여러가지 시장을 타겟으로 하고 있다. 하지만 주 전쟁터인 휴대 디바이스에서는 ARM이 가상
의 적이다.
거기서 Intel의 Silverthorne의 설계에서 중시한 것은, PC용 CPU의 로우엔드에 위치하는 LPIA판과
동등 이상의 퍼포먼스를, 더욱 낮은 TDP(Thermal Design Power) 열설계소비전력 과 평균소비전력에
서 실현하는 것이었다.
PC용 CPU의 LPIA판에서는 트랜지스터 수가 많은 뚱뚱한 CPU 코어를 저전압에서 저주파수로 동작시키
고 있다. 반면의 silverthorne의 기본적인 발상은, 트랜지스터 수가 적은 CPU를 저전압인 채로, 보
급형 CPU로서는 높은 주바수로 동작시켜, 그 결과로 PC용 CPU보다 훨씬 높은 퍼포먼스/소비전력을
실현하는 것이다. Silverthorne은 1.86GHz로 시장에 등장할 예정이다. 1.86Ghz는 PC용 통상전압판
CPU와 비교하면 낮다. 하지만 1GHz이하 구동이 대부분인 휴대기기용 프로세서 중에서는 상당히 높다
.
Intel은 현재 LPIA로서 90nm프로세서판의 Pentium M[Dothan]을 베이스로 한 [A100/A110(Stealey)]을
제공하고 있다. Stealy는 Dothan을 600~800MHz로 동작시켜, TDP를 3W까지 떨어뜨렸다 (종래의 ULV(
초저전압)판 Pentium M은 5.5W가 최저) Intel은 이전부터 Silverthorne의 퍼포먼스 레벨이 Stealey
와 동등하거나 그 이상이라고 설명했다.
2월3일~7일동안 샌프란시스코에서 개최된 ISSCC에서 밝혀진 Silverthorne의 아키텍쳐를 살펴보면 어
떻게 이 성능 레벨을 달성하고 있는지, 그 의문의 일부가 풀린다.
* Dothan 베이스의 Stealey와 동등 이상의 퍼포먼스
Intel은 고객들에게 Silverthorne 1.86GHz의 퍼포먼스는 Stealey 800MHz와 비교하는 경우, 싱글 스
레드 에서는 10%정도 높고, 멀티스레드 에서는 최대 40%까지 높아진다고 설명했다고 한다. 이것은
정수연산과 부동소수정연산 양쪽에 모두 해당된다고 한다.
간단하게 말하면 Silverthorne은 PC용 CPU의 1/2 규모의 CPU 코어를, 2배이상의 주파수로 동작을 시
켜서, 거의 동등한 싱글스레드 성능을 달성하고 있다. 작은 CPU코어를 빠르게 움직여서 퍼포먼스를
높인다는 발상이다. 추가로 하드웨어 멀티스레딩으로 멀티스레드 성능을 올리고 있다. 멀티스레드에
서 퍼포먼스를 번다. 이는 미디어 어플리케이션을 지향하는 설계의 CPU이다.
참고로 Intel은 Silverthorne의 CPU 코어가, Core MA의 1/4의 규모라고 ISSCC때에 설명했지만, 다이
면적을 비교해보면 1/2정도이다. 트랜지스터 수를 생각해봐도 Core MA의 CPU코어는 1900만개 이므로
그 1/2인 1000만개 정도가 Silverthorne코어로서 적당한 사이즈가 될 것이다. 1000만개보다 적으면
CPU코어의 규모로서는 상당히 어려워 진다. 그때문에 Intel이 Core MA에 대해서 Silverthorne의 CPU
코어가 1/4라고 설명하고 있는 것은 듀얼코어 CPU과 비교한 비율이라고 추정된다. 어느쪽이든,
Silverthorne의 코어가 PC용 CPU보다 상당히 작은 것은 확실하다.
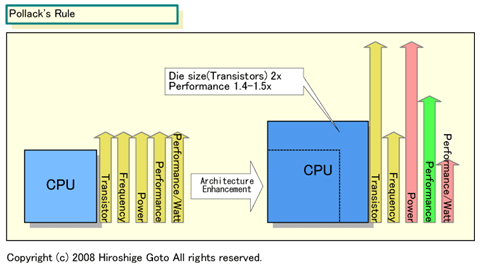
이유는 명료한데, 작고 심플한 CPU코어 쪽이 전력효율이 높기 때문이다. CPU 설계의 유명한 경험칙
으로, 갈은 프로세스 기술로 싱글코어 CPU의 다이사이즈(=트랜지스터수)를 2~3배로 늘려도, 정수연
산 퍼포먼스는 그 평방한(약 1.4~1.7배)정도밖에 올라가지 않는다는 규칙이 있다. Intel은 이것을 [
폴락의 법칙]이라고 부르고 있다. 이 법칙에 따르면, CPU 코어가 Core MA의 1/2 규모인
Silverthorne은 정수연산 퍼포먼스는 0.7배로 떨어진다. 하지만 CPU코어 부분의 소비전력은 반으로
떨어지기 때문에 퍼포먼스/소비전력과 퍼포먼스/다이는 1.4배로 올라가게 된다.
그럼, 절대 퍼포먼스의 낮은 반쪽은 어떻게 커버할 것인가. 그것은 주파수의 향상으로 커버한다는
것이 Intel의 전략이다. 무리하게 주파수를 올리는 것으로 전력효율을 떨어뜨리지 않고 퍼포먼스를
올려서 PC용 CPU의 LPIA판과 같은 레벨을 유지한다는 발상으로 생각된다.
* 멀티스레딩으로 퍼포먼스가 향상
참고로 Intel이 Silverthorne에서 싱글스레드 성능을 올리는 것으로 트랜지스터를 올리지 않고, 멀
티스레드 성능향상을 보게 된 것도, 마찬가지로 전력효율성의 이유이기 때문이다. 싱글스레드 성능
을 올릴려고 하면 소비하는 트랜지스터 수 당 퍼포먼스 향상의 폭이 작다. 다시 말해 효율이 나쁘다
. 그에 비해 멀티스레드 성능을 올리는 쪽이 전력효율은 좋아진다.
특히 Silverthorne의 경우는 멀티스레드에 의해 실행 파이프가 메꾸어지는 이점이 있다.
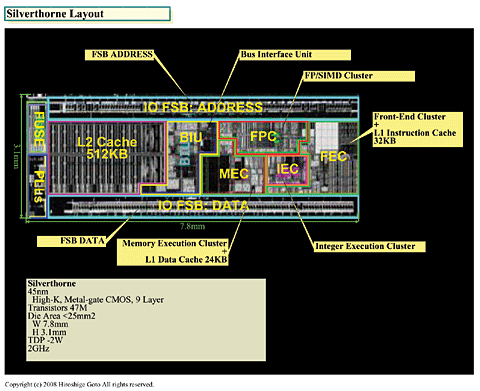
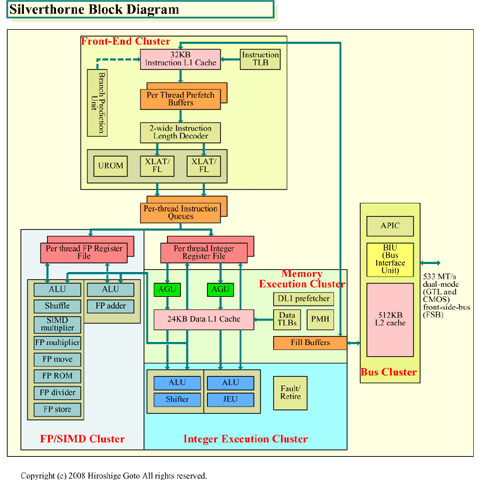
Silverthorne의 마이크로 아키텍쳐는 듀얼이슈로 인오더 방식이다. 명령유닛은 2명령을 동시에 실행
유닛 군에 대해 발행할 수 있다. 실행 파이프라인도 정수연산계와 부동소수점연산계 각각 2개씩 준
비하고 있다.
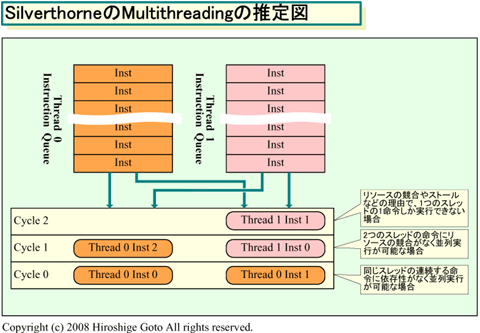
이 구성의 경우, 싱글스레드 실행이라면, 연속하는 명령 사이에 의존성이 없고, 리소스도 경합하지
않는 경우에서만 병렬로 실행될 수 밖에 없다. 그에 반해 Silverthorne은 실행 유닛 군에 대해서 2
명령을 발행할 때 스레드 스케줄링을 하고 있다. 발행하는 2명령을 1개의 스레드에서 선택하는 것도
, 2개의 스레드에서 1명령씩 선택하는 것도 가능하다.
그때문에 예를들면 1스레드에서 1명령밖에 발행할 수 없는 경우, 또 하나의 명령발행 슬롯에, 또 하
나의 스레드의 명령을 발행할 수 있다고 추측된다. Silverthorne에서는 싱글스레드 실행에서는 CPU
리소스가 쓸모없이 열려버리는 사이클을, 2스레드 실행으로 인해 메울 수 있다. 멀티스레딩은 메모
리 레이턴시의 은폐에도 효과가 있다. 하지만 SMT에 의한 Silverthorne의 멀티스레딩의 경우는 파이
프라인의 충전도 중요한 요소이다.
Intel의 ISSCC의 논문에 따르면, Silverthorne의 멀티스레딩은 전력은 15% 증가시켰지만, 퍼포먼스
는 30%까지 올렸다고 한다. 이 수치 대로라면, 멀티스레드 화로 인해, 퍼포먼스/소비전력이 더욱 향
상되었다는 것이다.
* 부동소수점연산의 향상을 고려한 마이크로 아키텍쳐
작은 CPU코어를 빠르게 돌린다. Silverthorne의 설계의 이 특징은, 여러가지 것을 시사하고 있다.
먼저 명료한 것은, Intel이 휴대전화에서도 장래에는 부동소수점연상 퍼포먼스가 중요하다고 생각하
고 있는 것이다.
일반론으로는 인오더 실행에서 파이프라인 단수를 늘이면, 동작주파수는 올라가지만, 정수연산 성능
이 상대적으로 덜 올라간다. 분기예측 미스의 패널티가 커지고, 동작주파수가 올라가는 만큼 메모리
로드 대기에서 스톨 하는 사이클도 올라가기 때문이다. 물론 멀티스레드 화로 인해 메모리 로드를
기다리는 스톨에 의한 현상은 어느정도 커버된다. 그러나 싱글스레드의 정수연산 성능은 올라가지
않는다.
한편, 파이프라인이 깊어짐에 따라 부동소수점연산의 퍼포먼스는 쉽게 올라간다. 분기가 적은 부동
소수점연산 중심의 코드는, 데이터만 순조롭게 필드되어 있다면 주파수의 향상에 응해 성능이 올라
가기 때문이다. 이 원칙에 따르면 Silverthorne은 부동소수점연산을 중시한 설계라는 이야기가 된다
.
애당초 실제로 Silverthorne의 정수연산과 부동소수점연산의 성능은 각각 Stealey를 살짝 넘은 정도
이다. 특히 부동소수점연산이 향상된 것은 아니다. 그 이유는 Silverthorne에서는 비용이 높은(=트
랜지스터 수를 소비하는) 부동소수점연산 유닛의 설계를 줄이고 있기 때문이라고 추정된다. 작아도
비교적 저성능인 부동소수점연산 유닛을 빨리 돌리는 것으로 Stealey와 같은 레벨의 부동소수점연산
성능을 유지한다고 생각하면 앞뒤가 맞는다.
하지만 silverthorne의 기본설계가 고주파수에 있다는 것은, 장래적인 확장의 가능성을 시사하고 있
다. 장래의 발전계 CPU 코어에서 부동소수점연산 유닛을 강화하는 경우에는 주파수가 높은
Silverthorne의 기본 아키텍쳐 덕분에 퍼포먼스가 크게 올라갈 것이다.
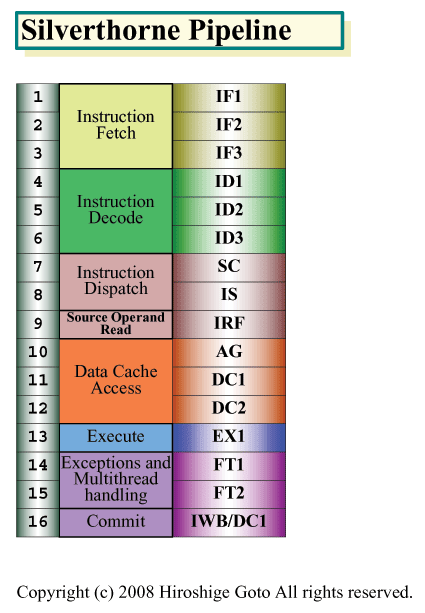
* 저속이지만 소비전력이 작은 트랜지스터를 채용
Silverthorne은 1사이클 실행에서 가능한 한 높은 주파수를 노리는 파이프라인 구성으로 되어있다.
파이프라인은 16스테이지로 Pentiru M계의 13스테이지보다 길게 보이지만, Silverthorne의 파이프라
인에는 L1 데이터 캐쉬 억세스의 3스테이지가 들어가 있다.
데이터 캐쉬 억세스를 추가한 것은 X86의 [Load-Op-Store]형 오퍼레이션을 그대로 실행하는 것으로
최적화 하고 있기 때문이다. 실행 스테이지의 앞에서 데이터 로드를 끼워넣은 편성을 하는 것으로
데이터 로드 대기의 스톨을 없앤다.
이 어프로치는 x86계의 CPU에서는 비교적 대중적인 것으로, Centaur Technology의 [C7]이나 오래전
에는 Cyrix의 [6x86]도 이 수법을 채용했다. 캐쉬 억세스 이외의 파이프라인 단수는, Silverthorne
도 Pentium M도 바뀌지 않는다. 하지만 인 오더 실행의 Silverthorne 쪽에 보다 심플하고, 각 스테
이지의 로직이 적게 끝난다. 다시 말해 Core MA나 Pentium M과 비교하면, Silverthorne은 파이프라
인의 길이로 필요한 게이트 수가 적다. 그것을 같은 정도의 스테이지로 자르고 있기 때문에
Silverthorne은 무리없이 고주파수화가 가능하다.
이 무리없이 라는 포인트는 중요하다. 예를들면 Silverthorne은 45nm 프로세스 에서도, PC용 CPU와
는 트랜지스터가 약간 다르게 되어 있다. PC용 CPU는 고속화를 위해 크리티컬 패스 등에서는 채널
길이가 짧고 고속이지만 리크 전류(Leakage)가 약간 많은 트랜지스터를 사용한다. 그에 반해
Silverthorne에서는 모든 트랜지스터가 채널길이가 길고 저속이지만 리크 전류가 작은 타입으로 되
어있다고 한다.
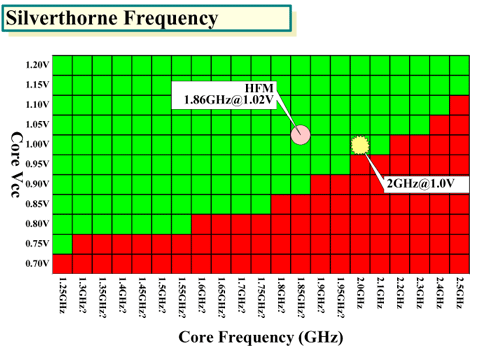
Silverthorne에서는 트랜지스터를 고속으로 하지 않아도, 낮은 전력과 전압으로 그럭저럭인 고주파
수를 달성할 수 있다. 그 때문에 CPU 코어가 작고, 명령의 병렬성이 낮아도, 일정 TDP 안이라면, PC
용 CPU를 향상하는 퍼포먼스를 달성할 수 있다. 그것이 Silverthorne의 마이크로 아키텍쳐의 특징이
다.
출처 : watch.impress.co.jp